

こんにちは。岡本です。
Pythonのデータ分析ライブラリであるPandasには、データの読み込み、加工、解析、出力を簡単に行える機能が盛り込まれています。本記事では、Pandasを使った基本的なデータ操作について、具体例を交えながら解説していきます。
Pandasの基本機能と使い方について
Pandasのインポート
まず、Pandasを使用するために、ライブラリをインポートします。下記はPandasをpdというエイリアスでインポートしています。
import pandas as pd
データの読み込み
Pandasを使うためには、データを読み込む必要があります。Pandasは様々な形式のデータを読み込むことができます。以下に、いくつかの例を示します。
# CSVファイルの読み込み
df = pd.read_csv('data.csv')
# Excelファイルの読み込み
df = pd.read_excel('data.xlsx')
# SQLクエリ結果の読み込み
import sqlite3
conn = sqlite3.connect('database.db')
df = pd.read_sql_query('SELECT * FROM table_name', conn)
これにより、データはPandasのDataFrame(データフレーム)という形式で読み込まれ、各種操作が可能になります。
Pandasの主要なデータ構造。行と列からなる2次元の表形式で成る。これにより、Excelのスプレッドシートのようにデータを操作できる。
データの表示
データが正しく読み込まれたか確認する場合は、下記のコードでデータフレームの先頭や末尾の数行を表示可能です。デフォルトでは5行ですが、引数に数値を渡すことで任意の行数を表示できます。
# 先頭の5行を表示
print(df.head())
# 末尾の5行を表示
print(df.tail())
# 先頭の10行を表示
print(df.head(10))
# 末尾の3行を表示
print(df.tail(3))
また、全体の構造を把握するために、データフレームの基本情報を表示することもできます。
# データフレームの情報を表示
print(df.info())
データの基本統計量を確認するには、describeメソッドを使います。
# 統計量の表示
print(df.describe())
データの基本的な特性を表すもの。分布全体を一つの数で表す代表値とデータのばらつきの大きさを表す散布度に大きく分けられる。平均値、中央値、最大値、最小値などがある。
列の選択
データフレームから特定の列を抽出したいシーンは多いでしょう。単一の列、または複数の列を選択する方法を示します。
# 単一の列を選択
print(df['column_name'])
# 複数の列を選択
print(df[['column_name1', 'column_name2']])
行のフィルタリング
特定の条件に基づいてデータフレームの行をフィルタリングする方法も重要です。例えば、特定の列の値が一定の条件を満たす行のみを抽出する場合です。
# 条件に一致する行を選択
filtered_df = df[df['column_name'] > value]
新しい列の作成
既存の列を用いて新しい列を作成することもよく行われます。例えば、2つの列の値を足し合わせて新しい列を作成する場合です。
# 新しい列を追加
df['new_column'] = df['column1'] + df['column2']
データのグループ化と集計
データを特定の列でグループ化し、各グループごとに集計する方法を紹介します。
# グループ化して集計
grouped_df = df.groupby('column_name').sum()
この方法を使うことで、例えば売上データを地域ごとに集計することが可能です。
データの並び替え
特定の列に基づいてデータを並び替える方法です。昇順または降順に並び替えることができます。
# 昇順に並び替え
sorted_df = df.sort_values('column_name')
# 降順に並び替え
sorted_df = df.sort_values('column_name', ascending=False)
欠損値の処理
データには欠損値(NaN)が含まれることがあります。この欠損値を扱う場合の例が下記です。
# 欠損値を持つ行を削除
df_dropped = df.dropna()
# 欠損値を特定の値で置換
df_filled = df.fillna(value)
データの保存
最後に、加工や分析したデータをファイルに保存する方法です。
# CSVファイルに保存
df.to_csv('output.csv', index=False)
# Excelファイルに保存
df.to_excel('output.xlsx', index=False)
実例
これまでの内容を踏まえて、架空の社員データを含む、下記CSVファイル(employees.csvとします)を操作してみましょう。
id,name,department,salary,hire_date
1,John,Sales,50000,2018-01-15
2,Alice,HR,60000,2017-03-22
3,Bob,Sales,55000,2019-05-10
4,Charlie,IT,70000,2016-11-01
5,Diana,IT,75000,2019-08-25
6,Eva,HR,58000,2020-02-15
7,Frank,Sales,52000,2018-07-11
8,Grace,IT,72000,2020-06-30
9,Henry,HR,63000,2015-04-12
10,Ivy,Sales,51000,2017-12-05
このデータを用いて、実際に基本的なデータ操作を行うコードを以下に示します。
import pandas as pd
# CSVファイルの読み込み
df = pd.read_csv('employees.csv')
# データの表示
print("先頭の5行:")
print(df.head())
# 基本情報の取得
print("\nデータフレームの情報:")
print(df.info())
print("\n統計量の表示:")
print(df.describe())
# 列の選択
print("\n名前列:")
print(df['name'])
print("\n名前と部門列:")
print(df[['name', 'department']])
# 行のフィルタリング
filtered_df = df[df['salary'] >= 60000]
print("\n給与が60000以上の社員:")
print(filtered_df)
# 新しい列の作成
df['annual_salary'] = df['salary'] * 12
print("\n年収列を追加:")
print(df)
# データのグループ化と集計
grouped_df = df.groupby('department')['salary'].mean().reset_index()
print("\n部門ごとの平均給与:")
print(grouped_df)
# データの並び替え
sorted_df = df.sort_values('salary', ascending=False)
print("\n給与の降順で並び替え:")
print(sorted_df)
# 欠損値の処理(今回は例としてsalary列の欠損値を50000で置換)
df_filled = df.fillna({'salary': 50000})
print("\n欠損値を50000で置換したデータ:")
print(df_filled)
# データの保存
df.to_csv('output_employees.csv', index=False)
df.to_excel('output_employees.xlsx', index=False)
このコードを実行することで、employees.csvからデータを読み込み、基本的なデータ操作を行い、その結果を確認することができます。Pandasの様々な機能を駆使してデータを分析し、結果を保存することが可能です。
実行した結果を下記に示します。
先頭の5行:
id name department salary hire_date
0 1 John Sales 50000 2018-01-15
1 2 Alice HR 60000 2017-03-22
2 3 Bob Sales 55000 2019-05-10
3 4 Charlie IT 70000 2016-11-01
4 5 Diana IT 75000 2019-08-25データフレームの情報:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 10 non-null int64
1 name 10 non-null object
2 department 10 non-null object
3 salary 10 non-null int64
4 hire_date 10 non-null object
dtypes: int64(2), object(3)
memory usage: 528.0+ bytes
None統計量の表示:
id salary
count 10.00000 10.000000
mean 5.50000 60600.000000
std 3.02765 9118.966803
min 1.00000 50000.000000
25% 3.25000 52750.000000
50% 5.50000 59000.000000
75% 7.75000 68250.000000
max 10.00000 75000.000000名前列:
0 John
1 Alice
2 Bob
3 Charlie
4 Diana
5 Eva
6 Frank
7 Grace
8 Henry
9 Ivy
Name: name, dtype: object名前と部門列:
name department
0 John Sales
1 Alice HR
2 Bob Sales
3 Charlie IT
4 Diana IT
5 Eva HR
6 Frank Sales
7 Grace IT
8 Henry HR
9 Ivy Sales給与が60000以上の社員:
id name department salary hire_date
1 2 Alice HR 60000 2017-03-22
3 4 Charlie IT 70000 2016-11-01
4 5 Diana IT 75000 2019-08-25
7 8 Grace IT 72000 2020-06-30
8 9 Henry HR 63000 2015-04-12年収列を追加:
id name department salary hire_date annual_salary
0 1 John Sales 50000 2018-01-15 600000
1 2 Alice HR 60000 2017-03-22 720000
2 3 Bob Sales 55000 2019-05-10 660000
3 4 Charlie IT 70000 2016-11-01 840000
4 5 Diana IT 75000 2019-08-25 900000
5 6 Eva HR 58000 2020-02-15 696000
6 7 Frank Sales 52000 2018-07-11 624000
7 8 Grace IT 72000 2020-06-30 864000
8 9 Henry HR 63000 2015-04-12 756000
9 10 Ivy Sales 51000 2017-12-05 612000部門ごとの平均給与:
department salary
0 HR 60333.333333
1 IT 72333.333333
2 Sales 52000.000000給与の降順で並び替え:
id name department salary hire_date annual_salary
4 5 Diana IT 75000 2019-08-25 900000
7 8 Grace IT 72000 2020-06-30 864000
3 4 Charlie IT 70000 2016-11-01 840000
8 9 Henry HR 63000 2015-04-12 756000
1 2 Alice HR 60000 2017-03-22 720000
5 6 Eva HR 58000 2020-02-15 696000
2 3 Bob Sales 55000 2019-05-10 660000
6 7 Frank Sales 52000 2018-07-11 624000
9 10 Ivy Sales 51000 2017-12-05 612000
0 1 John Sales 50000 2018-01-15 600000欠損値を50000で置換したデータ:
id name department salary hire_date annual_salary
0 1 John Sales 50000 2018-01-15 600000
1 2 Alice HR 60000 2017-03-22 720000
2 3 Bob Sales 55000 2019-05-10 660000
3 4 Charlie IT 70000 2016-11-01 840000
4 5 Diana IT 75000 2019-08-25 900000
5 6 Eva HR 58000 2020-02-15 696000
6 7 Frank Sales 52000 2018-07-11 624000
7 8 Grace IT 72000 2020-06-30 864000
8 9 Henry HR 63000 2015-04-12 756000
9 10 Ivy Sales 51000 2017-12-05 612000コードの50、51行目で出力したcsvとexcelの中身はこちらです。プログラムで追加した、annual_salaryの列が出力されています。
id,name,department,salary,hire_date,annual_salary
1,John,Sales,50000,2018-01-15,600000
2,Alice,HR,60000,2017-03-22,720000
3,Bob,Sales,55000,2019-05-10,660000
4,Charlie,IT,70000,2016-11-01,840000
5,Diana,IT,75000,2019-08-25,900000
6,Eva,HR,58000,2020-02-15,696000
7,Frank,Sales,52000,2018-07-11,624000
8,Grace,IT,72000,2020-06-30,864000
9,Henry,HR,63000,2015-04-12,756000
10,Ivy,Sales,51000,2017-12-05,612000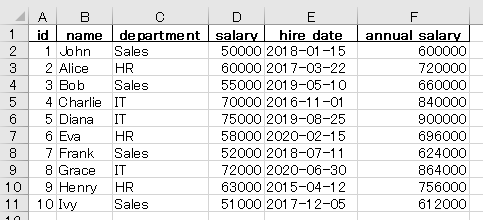
まとめ
Pandasを使うことで、データの読み込みから加工、解析、保存まで、一連の作業を非常に効率的に行うことができます。本記事で紹介した基本操作を組み合わせることで、様々なデータに対して柔軟に対応できるようになるでしょう。
Pandasの持つ豊富な機能を活用することで、より高度なデータ操作や分析が可能になります。Pandasの公式ドキュメントも非常に充実しているので、必要に応じて参考にしてみてください。
Pandasを使ってデータ操作をマスターし、データ分析のスキルを向上させていきましょう!


コメント